
The PAYNEful Portfolio – On Parsing Text and HTML with PHP

I’ve had a bit of dabbling with reading and interpreting text using PHP recently, specifically for two personal projects:
- A “translator” that reads in text and converts it to “fake French” (in the style of other silly “translators”).
- A simple application that reads and organises HTML bookmark files (as in the ones exported from browsers) into a new HTML file.
Both are very similar in terms of what they do, and I just wanted to update this often-neglected section of the website with some brief words on how both projects work and, on reflection, why PHP is just bloody awful for parsing the written word.
The Silly French Translator
I don’t have any particular clues about how other translators work, but I get the feeling that they are possibly operating on the same basis as how mine came to be – a massive series of case-by-case replacements built up via trial-and-error. I suspect that professional linguists could help form some form of complex linguistic algorithm that would make the find-and-replace process easier, but by not having access to that sort of knowledge I just had to “brute force” the replacements until there was something approaching recognisable “fake French”.
The main problem with find-and-replace in PHP is that it is not just a simple case of having a massive list of str_ireplace statements. That’s how the script began, certainly, but suddenly you will find certain string replacements treading on the toes of other string replacements. For example, one statement I had to comment out from the script was the following:
$text = str_ireplace('en','on',$text);
It looks a fairly simple replacement and, in many cases, captures the “French” pronunciation of “on” quite nicely (an example being “I left ze newspapair en ze sofa”). However, by replacing all instances of “on” in entered text it suddenly mucks up the following statements:
$text = str_ireplace('shion','she-on',$text);
$text = str_ireplace('sion','she-on',$text);
Suddenly words like “station” become “statien” and not “stashe-on”. With the complex, inconsistent way English is put together, simple substitutions will never be correct in every single case.
There are a large amount of find/replacement statements in the script, all gleamed from trial-and-error by feeding in different chunks of text. Here’s a taste of what that looks like:
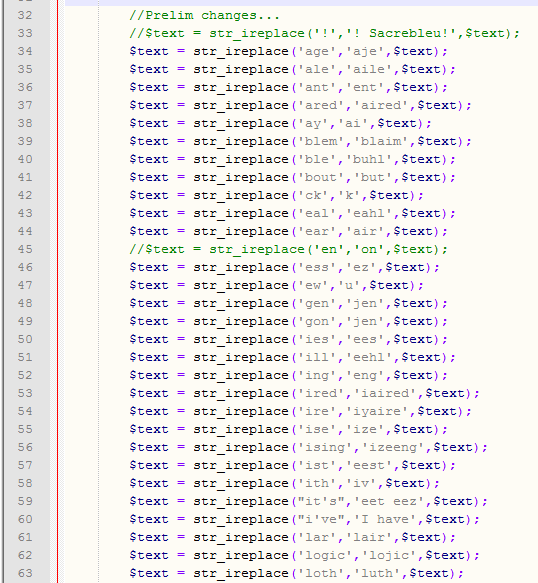
PHP really doesn’t have a better way of setting up multiple find/replacements, which makes for a bit of an eyesore when it comes to the code. I guess I could have done any of the following:
- Wrap the replacement operations in a function and invoke it once.
- Have a single find/replace statement inside a function and feed in the text variable.
- Load all the find/replacements into an array and then loop through.
At the end of the day there is no easy way to set up “if this, replace this” without having multiple statements in PHP1, although that third option sounds like it would be more manageable (not quite sure why I didn’t do it that way to be honest!).
Where the generic replacements weren’t sufficient, I had to then explode whatever text had been entered into an array using spaces as a delimiter. Then it was just a case of looping through word-by-word and doing alterations based on case matches. There was a requirement to strip punctuation when comparing words as a full stop could completely muck up an exact match. For example, the script would not match the word “hello” if if was suffixed with an exclamation mark, “hello!”.
The cases in this “second half” of the script were a lot more specific that the generic replacements in the first part. Here’s a little example of the sort of thing in the latter part of the script:

For a bit of added flavour, the function that does all the processing2 also does a few randomised replacements. After all the other processing, it then splits all the text up using the letter “e” as a delimiter and then reassembles it, with there being a 1-in-4 chance of inserting an “e” with an accent rather than a regular “e”. Similarly the articles “the” and “and” are randomly replaced with stereotypically associated variants (“le”, “la”, “ze”, etc.)3.
All-in-all the translator does what it was supposed to, even if the code behind the scenes is a bit of a bloated pig. It is one of those scripts that will rarely ever be updated, and if I ever need to tweak it the replacements are fairly self-explanatory. I did briefly consider looking into having the ability to translate webpages but it all looks a little complicated for something that’s supposed to be a bit of fun, and there’s also implications of dealing with potential complaints from people who don’t want their websites “translated”.
The HTML Bookmark Sorter
This was a personal project undertaken for a selfish motivation of being too lazy to manually sort my bookmarks and I initially went in looking to only deal with Firefox .json backup files. However, after some brief investigation I realised that bookmark HTML files are all exported in the same format across various browsers, so I directed the project in that direction instead.
It seemed like a good idea at first because, aha, PHP has HTML parsing built-in. In theory you load the DOM object into PHP, loop through the nodes and away you go!
Unfortunately, HTML bookmarks all have the same de-facto standard of being absolutely awful non-standard HTML. The parser refused to recognise the DOCTYPE “NETSCAPE-Bookmark-file-1” and would stumble frequently on tags without a closing tag. I am baffled as to why malformed HTML is the bookmark standard, I can only assume it’s some form of legacy formatting from some version of a bygone Internet Explorer long forgotten (and good riddance)4.
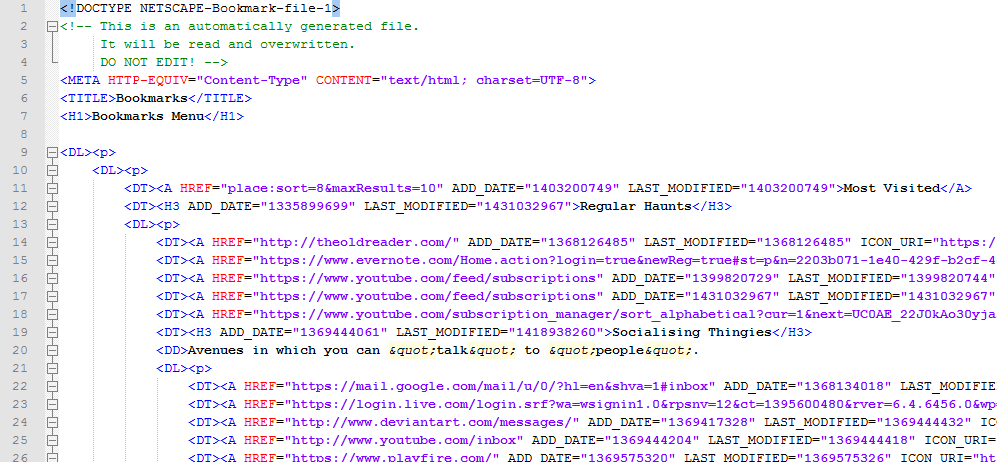
At this point I was already regretting abandoning the Firefox-specific JSON file interpreter. JSON is such a lovely format to work with, in PHP you just decode it and away you go, looping through those key-value pairs as much as you like!
The alternative, and this is considered a no-no by practically every topic on this subject on StackOverflow, is to use regex to match bits of the HTML. The argument against this is that HTML can be inconsistent and it would be near-impossible to catch every instance of something (much like the problem of the French translator). Almost every case recommended the DOM parser, which I couldn’t use in this case. My justification for using regex is that these files are computer-generated; they should be the same format every time (i.e. half-hearted HTML).
What the final script does is, after some basic validation (is the file type correct, does the file have the hallmarks of a Netscape bookmarks file, etc.), strip out all tags bar the anchor tags. It then converts these to an array using the tag as a delimiter and loops through, performing a few different regex matches and getting the information required: link, page title, timestamps, icon, etc.
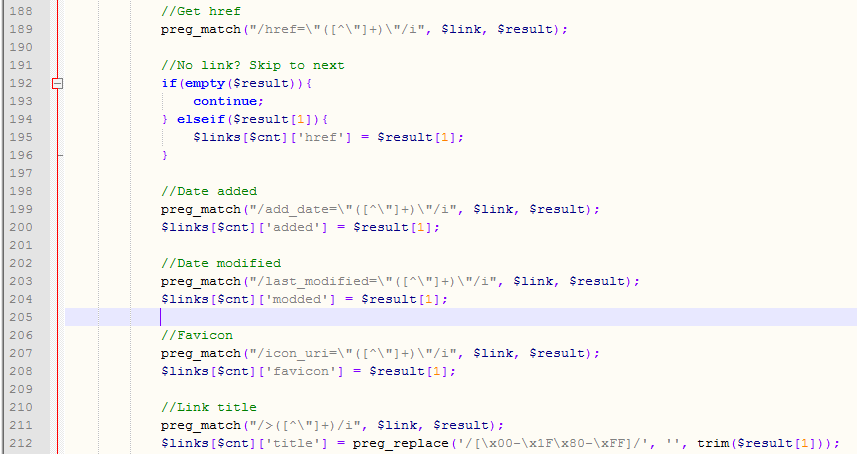
What follows is a series of array sorts and reassignments – there’s a chunk of string comparisons very much in the vein of the French translator and the same problem still occurs in that one comparison will override another. For example, the video games categorisation will always conflict with the shopping category – if you are a user of the popular digital game distributor Steam, your Steam bookmarks may slip into either the games category or the shopping category depending on whether the URL contains the word “shop”, which a lot of them do. Processing for shopping happens before games to try and avoid this, but it’s the ever-present problem that comparisons are very linear5.

The final result gets output into HTML and an “octet-stream” attachment is invoked to prompt the user to save the file. The original uploaded file is deleted from the server regardless of whether the operation succeeds6.
One odd quirk was that the files were originally not importing into browsers at all. Realisation dawned that it might be because the script was creating a HTML file where all the links were on one line. Forcing a new line on every row did the trick.
I would have liked to output some stats after the script has run – how many bookmarks were processed, how long it took, etc. However, the script runs fine “as-is” so I am reluctant to break it just for some idiosyncratic stats. Incidentally my personal bookmark count came in around the 3,500 mark and most of them were YouTube videos7.
With billions of websites out in the ether, my bookmark sorter probably accounts for 0.0000001% of the web (if that!) based around my tiny slice of life surrounding my internet activity. For the bookmark sorter to be truly valuable, it would be intelligent – it would probably go to every link8 and try to determine what the page is actually about, removing any bookmarks that result in a 404. It would be able to generate categories on-the-fly by detecting common themes, words and phrases. Sounds like a brilliant project, but it’s a little bit out of my scope. If you’re reading this and have the resources and inclination to build such an app, drop me a line sometime!
In Conclusion
If you have the time, knowledge and resources to build comparison functions that are genuinely intelligent, you’re either doing the web community a great service or (more likely) you’re not using PHP and instead are using a language more capable of parsing content. If, however, you just need some rudimentary comparisons that are a little bit “rough around the edges”, it’s definitely something that can be achieved in PHP quite nicely.
- I realise you can load an array of comparisons into str_replace but that’s for multiple matches in the same case, not in different cases. ↩
- This function is appropriately called “make_french()” as that’s what it does…ish. ↩
- I realise that French, like a lot of European languages, operates on a gender basis with masculine, feminine and neutral but for the purposes of “fake French” I wasn’t too precious about using correct cases when parsing text. ↩
- After some investigation it’s not Microsoft’s fault (for once), it’s a legacy format even older than IE6. ↩
- One “spitball” idea (throwing it out and seeing if it sticks) would be to use some form of points system and assign category points depending on the characteristics of the link and page title. If a link has 5 points in shopping (because it contains the words “store” and “buy”) and 7 points in games (because it’s for gog.com and contains the words “video games”), assign it to the games category. ↩
- Sure, I could be lying and collecting your bookmark files on the sly but I’ve got enough bookmarks, why in the hell would I want yours? ↩
- At the time of writing I am having great joy revisiting these videos, deleting crap ones and adding the interesting ones to my YouTube favourites, a sort of eternal pit of damnation for videos I have watched that will probably never be seen again. ↩
- Either fetch the page contents with wget or crawl the page Google-style. ↩
Post by Sean Patrick Payne+ | May 15, 2015 at 7:00 pm | Articles, Portfolio and Work, Projects, Projects, Technology | No comment
Tags: HTML, parsing, PHP, Please don't hate me for my horrible code, regex